FastAPI学習動画04 クエリーパラメータ
コメントを残す
FastAPIを使った解説動画です。
Windows WSL2でFast APIでHello Worldまで行いました。
いわゆるセイウチ演算子。Python 3.8から
今までこのように代入とif文での評価は一度にできませんでしたが、
s = "Hello World"
n = len(s)
if n > 10:
print("n is longer then 10")
else:
print("n is shorter than 10")
代入式を使うと、代入した結果をすぐに評価できるので少し楽。
s = "Hello World"
if (n := len(s)) > 10:
print("n is longer then 10")
else:
print("n is shorter than 10")
pipenvのライブラリインストール系のコマンドの意味がわからなくなるのでまとめました。
| install | update | sync | |
|---|---|---|---|
| 意味 | Pipfileからインストール | Pipfileに従ってアップデート | Pipfile.lockでインストール |
| Pipfile | 更新あり | – | – |
| Pipfile.lock | 更新あり | 更新あり | – |
Pipfileの依存関係ルールに従ってPipfileの全ライブラリをインストールする。
各ライブラリの依存関係がチェックされて、ルールにマッチするようにライブラリはアップデートされ、Pipfile.lockは更新される。
すでにライブラリがインストール済みのとき、ルールにマッチしていれば、アップデートがあっても最新に更新されることはない。
例えば、ルール上は >=2.0.0 で2.0.0がインストール済みのとき、2.0.1が公開されていてもアップデートはされない。新規にインストールするときは2.0.1が選択される。これをルールに合う最新にアップデートするときは、pipenv updateを使う。
依存関係のチェックが走るので遅い。
Pipfileの依存関係ルールを hoge=”==2.0.0″に更新後、そのルールに従って hoge ライブラリがインストールされる。
ルールを更新するのでPipfileが更新される、ルールに従ってライブラリが更新されるのでPipfile.lockも更新される。
依存関係のチェックが走るので遅い。
Pipfileの依存関係ルールに従ってPipfileの全ライブラリの更新をチェックしてルールに合う形で最新版にアップデートする。ルールは変更していないのでPipfileは更新されない。Pipfile.lockは更新される。
依存関係のチェックが走るので遅い。
Pipfile.lockに記載されたとおりにライブラリをインストールする。ルールは更新されないのでPipfileは更新されない。Pipfile.lockに合わせてインストールされるのでPipfile.lockも更新されない。
依存関係のチェックが走らないので早い。
Pipfile.lockを更新せずに、Pipfileからのインストールを試みる。Pipfile.lockがPipfileより古い場合にはエラーになる。--skip-lockよりは安全に、更新チェックをしつつインストールできる。
Pipfile.lockを更新せずにインストールを行う。Pipfileのルールに従ってインストールが行われるがPipfile.lockは更新されないだけで、Pipfile.lockと同じとおりにインストールされるわけではない。Pipfile.lockを完全無視するのでpipenv syncのほうが良い。
例:ルール上は >=2.0.0 でPipfile.lockが2.0.0。2.0.1が公開されていて、ローカルには未インストールの場合、インストールされるのはルールにマッチする最新の2.0.1だが、Pipfile.lockは更新されないため、環境の再現にはならない。
datetime.datetimeのオブジェクトをUTCやJSTに変換するさいのパターンを網羅してみます。
datetime型には、timezone情報がついているかどうかの区別がある。timezone情報があるもの=aware。ないもの=native。
timezoneを扱う場合はdateutilを使用するのが今日では一般的のよう。
ひとまずここでは、Python3.9以前のことも考慮してdateutilを使用します。
pip install python-dateutil
from datetime import datetime
from dateutil import tz
JST = tz.gettz('Asia/Tokyo')
UTC = tz.gettz("UTC")
2021/04/01 11:22:33(UTC)を例に生成するパターン
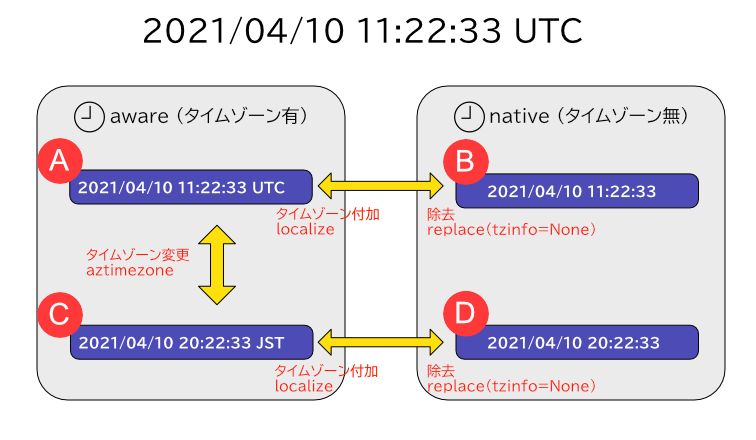
| タイムゾーンあり(aware) | タイムゾーンなし (native) | |
|---|---|---|
| UTC | A) 2021/04/01 11:22:33 UTC | B) 2021/04/01 11:22:33 |
| JST | C) 2021/04/01 20:22:33 JST | D) 2021/04/01 20:22:33 |
UTCのタイムゾーンをもつawareなdatetimeを作成するには、tzinfoにタイムゾーンを渡す。
>>> A = datetime(2021, 4, 1, 11, 22, 33, tzinfo=UTC)
>>> A.isoformat()
'2021-04-01T11:22:33+00:00'
※(pytzを使う場合)ちなみにtzinfoを渡す方法をpytzで行うと、問題が発生するのでpytzのときにはこの方法は使わず、localizeメソッドを使うこと。
>>> datetime(2021, 4, 1, 11, 22, 33, tzinfo=pytz.timezone("Asia/Tokyo")) # これは間違い
datetime.datetime(2021, 4, 1, 11, 22, 33, tzinfo=<DstTzInfo 'Asia/Tokyo' LMT+9:19:00 STD>)
^^
>>> pytz.timezone("Asia/Tokyo").localize(datetime(2021, 4, 1, 11, 22, 33))
datetime.datetime(2021, 4, 1, 11, 22, 33, tzinfo=<DstTzInfo 'Asia/Tokyo' JST+9:00:00 STD>)
普通にdatetimeのインスタンスをタイムゾーン情報なしに作成する。
タイムゾーンは持たないので、それがUTCの時刻かどうかは明示できない。
>>> B = datetime(2021, 4, 1, 11, 22, 33)
>>> B.isoformat()
'2021-04-01T11:22:33'
Aと同様。
>>> C = datetime(2021, 4, 1, 20, 22, 33, tzinfo=JST)
>>> C.isoformat()
'2021-04-01T11:22:33+09:00'
設定する時刻が違うだけで、B)と同様。
>>> D = datetime(2021, 4, 1, 20, 22, 33)
>>> D
datetime.datetime(2021, 4, 1, 20, 22, 33)
UTCタイムゾーンのAをJSTタイムゾーンに変換するときはと astimezoneメソッドを使用。
これはCに一致する。UTCにおける11:22:33から+9時間されて20:22:33になる。逆も同様。
>>> A.astimezone(JST)
datetime.datetime(2021, 4, 1, 20, 22, 33, tzinfo=<DstTzInfo 'Asia/Tokyo' JST+9:00:00 STD>)
>>> A.astimezone(JST) == C
True
>>> C.astimezone(UTC)
datetime.datetime(2021, 4, 1, 11, 22, 33, tzinfo=<UTC>)
>>> C.astimezone(UTC) == A
True
awareなdatetimeからnativeなdatetimeにするのは、あまりないかもしれないが、replaceでtzinfoをNoneに設定すればできる。
ただしこれは本当にタイムゾーンを除去するだけで、時刻が変換されるわけではないので注意。
あるタイムゾーンからあるタイムゾーンへ置き換えるときはreplaceで置き換えてはいけない。前述のastimezoneを使うこと。
>>> A.replace(tzinfo=None)
datetime.datetime(2021, 4, 1, 11, 22, 33)
nativeなdatetimeではタイムゾーンは持たないが、それを別のタイムゾーンのもの時間へシフトしたい場合。
直接変更するのではなく、replaceでaware化してからastimezoneで変換、再びreplaceでnative化する。
# UTCとみなしてあとに、JSTへ変換し、再びnative化
>>> B.replace(tzinfo=UTC).astimezone(JST).replace(tzinfo=None)
datetime.datetime(2021, 4, 1, 20, 22, 33)
2つのタイムゾーンのoffsetの差をtimedeltaで加算することでも可能だが、その場合はそのタイムゾーンのオフセットが日時によって変わることを考慮する必要になる。たとえば夏時間など。上記の方法で awareなdatetimeにしてから変換するとその問題は発生しないので安全。
非同期IOを使うことでシングルプロセス、シングルスレッドでも効率的に複数のHTTPリクエストの処理を行う。
はじめに動作確認用に複数のリクエストを処理できるHTTPサーバプログラムを用意する。
このサーバープログラム自体も非同期IOで記述することで複数のリクエストを処理するサーバーを記述できるのだが、サーバー側とクライアント側で非同期IOの説明すると、今回の論点がぼやけてくるので、ひとまずリクエストを受け付けると3秒待ってからレスポンスを返すマルチスレッドなサーバーを用意した。このプログラムの説明は本題ではないので省略。
これを起動して、別の端末からcurlで同時に3リクエストを送ってみると、3秒後に3つのレスポンスが返る。
$ python wsgi-server.py
$ seq 1 3 | xargs -P 3 -I{} curl "localhost:8000/{}"
Hello World/1
Hello World/2
Hello World/3
サードパーティライブラリのaiohttpを使用すると、非同期なHTTPClientをかんたんに記述できる。
import aiohttp
import asyncio
import time
async def get_request(session, no):
response = await session.get(f'http://localhost:8000/{no}')
content = await response.text()
print(f"{time.strftime('%X')} - {response.status} {content}", end='')
async def main():
tasks = []
print(f"{time.strftime('%X')} - Start")
async with aiohttp.ClientSession() as session:
for n in range(3):
tasks.append(get_request(session, n+1))
await asyncio.gather(*tasks)
print(f"{time.strftime('%X')} - Finish")
asyncio.run(main())
実行結果
18:03:56 - Start
18:03:59 - 200 Hello World/3
18:03:59 - 200 Hello World/2
18:03:59 - 200 Hello World/1
18:03:59 - Finish
Python3.7以降から使用可能なasyncioモジュールを使用することで非同期処理IOが実装できる。
非同期IO処理とは、簡単に言えば「あるIO処理の終了を待たずに他の処理をする」こと。今までであれば時間のかかる処理を呼び出せば、その処理が終了するまで処理は止まって(ブロックされて)待たなければならなかった。これが同期処理。非同期処理は処理の終了を待たずに、その間に他の処理をできる。(ノンブロックキング)
threadingやmultiprocessでも似たように、処理の終了を待たずに他の処理をすることができるが、asyncioによる非同期IO処理はそれよりももっと軽量に動作し、実際には並列して処理が動くことはなく1スレッドで動いている処理は1つだけになる。
「同時に処理が動かない」のに「処理の終了を待たずに他の処理ができる」のは奇妙に思うかもしれない。IO処理というのはCPUを使わず処理が終わるのを待っている時間がある。例えばファイルの読み込みをしている間は、CPUを使わずにファイルのデータが読み込まれるのを待っている。この時間はCPU的には十分に長い時間なのでこの時間に他のことが処理できる。
非同期IO処理は「空き時間にこの処理をして!終わったら教えて!」という細かい処理をどんどん登録して、「空いた!」「じゃあこれやって!」という小さな処理単位をイベントループというループの中でどんどん処理する。処理自体は同時に1つしかこなせないが、空き時間を有効活用していることになる。ちょうど料理中に電子レンジをONにして、チンと完了するまでに他の作業をするのに似た感じ。
処理単位のなかで、長く時間のかかるブロッキング処理をしてしまうと、従来の同期処理と同じことになってしまうため避けなければならない。
例えばtime.sleepはスリープする処理だが、これは同期処理のsleepであり、非同期IOにはasyncio.sleepという非同期用のsleepがある。間違って非同期処理の中で、time.sleepを使うと非同期処理は他の処理をプログラムはそこでブロックして他のことを処理できなくなる。
このため、今まで同期処理でやっていたことと違うコードを書くことになるので注意する必要がある。
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(f"{time.strftime('%X')} - {what}")
async def main():
print(f"{time.strftime('%X')} - start")
c1 = say_after(1, 'hello')
c2 = say_after(2, 'world')
await asyncio.gather(c1, c2) #2つの処理の終了を待つ
print(f"{time.strftime('%X')} - finish")
# 非同期IOのエントリポイント
asyncio.run(main())
実行結果
16:10:28 - start
16:10:29 - hello
16:10:30 - world
16:10:30 - finish
1秒後にhelloと出力する処理、2秒後にworldと出力する処理を実行する。say_after関数は完了を待たずにすぐに返ってくる。asyncが設定された関数はそのような処理になる。asyncが設定された関数の処理を待つ場合にはawaitを使う。待つと書いたが実際にはこの間に他のasync処理を実行して、終わった後に戻ってくるような動きをする。
この結果、2つのsay_afterの処理はそれぞれ1秒、2秒まってから処理が行われるので全体としては2秒ですべてが終了する。
awaitが使えるのはasync関数の中だけになる。これが重要でasyncで非同期処理を使いたいと思ったときにはそこがasyncでなければならない。それを呼び出す関数もasyncでなければならない。どんどん遡ったトップレベルのエントリポイントで、asyncio.runなどから起動されていなければならない。
await.sleepをtime.sleepにすると、sleepでブロックされてその他の処理ができなくなってしまう。
import asyncio
import time
async def say_after(delay, what):
# await asyncio.sleep(delay)
time.sleep(delay) # 非同期ioではないsleep
print(f"{time.strftime('%X')} - {what}")
async def main():
print(f"{time.strftime('%X')} - start")
c1 = say_after(1, 'hello') #time.sleepがブロックするのでc1の取得に1秒かかる
c2 = say_after(2, 'world')
await asyncio.gather(c1, c2) #2つの処理の終了を待つ
print(f"{time.strftime('%X')} - finish")
# 非同期IOのエントリポイント
asyncio.run(main())
実行結果
11:05:37 - start
11:05:38 - hello
11:05:40 - world
11:05:40 - finish
実行結果からわかるように、startからhelloまで1秒かかり、helloからworldに2秒かかっている。
3.6からフォーマット済み文字列リテラル(f-string)が使用できるようになりました。
文字列内で変数を参照する書き方です。フォーマット指定に関してはformat関数とほぼ同じです。
>>> a = 10
>>> print(f'aの値は{a}です')
aの値は10です
>>> print(f'aの値は{a:03d}です')
aの値は010です
>>> print(f'aの値は{a:.2f}です')
aの値は10.00です
日付などのフォーマットも利用可能
import datetime
>>> now = datetime.datetime.now()
>>> print(f'nowの値は{now:%Y/%m/%d %H:%M:%S}です')
nowの値は2021/02/10 12:12:43です
ちょっと便利な機能として、3.6からは=を書式指定に使うとその変数名を表示してくれます。
import datetime
>>> now = datetime.datetime.now()
>>> print(f'{now=}')
now=datetime.datetime(2023, 8, 26, 16, 12, 34, 392947)
書式指定としてf{now=}と書くだけで、now=値 のように表示されてデバッグのときに便利です。
>>> print(f"{now=:[%Y-%m-%d]}") # =のあとにフォーマット指定する例
now=[2023-08-26]
参考: フォーマット済み文字列リテラル