python3.5以降から使用可能な型ヒントを使う。これを使えばpythonでも静的言語なるように見えるが、実行時には完全に無視されチェックはなにも行われない。
現状では型ヒントのチェックツールでの構文チェックや、PyCharmなどの開発環境でのコード補完のためのヒントとなる点に注意する。
チェックツールmypyのインストール
これを使わないと型ヒントの情報はなにも活かせない。
$ pip install mypy
$ mypy -V
mypy 0.511
型ヒントなしのコード
型ヒントなしのコードとして、こんな関数があったとする。
def concat(a, b):
return a + b
a,bの双方に文字列を渡すケースを想定しているが、数値を渡すと(意図した操作ではないが)加算した結果が得られる。文字列と数値を渡すと実行時エラーになる。
concat("Hello", "World") # "HelloWorld"
concat(1, 2) # 3
concat("s", 2) # TypeError: must be str not int
型ヒントの付加
意図してない操作を除外したい。実行する前に静的に構文エラーとしたい。そのために型ヒントをつける。このように記述できるのはpython3.5以降。
def concat(s:str, n:str)->str:
return s + n
引数の型。関数の戻り値の型が情報として付加された。
mypyでの静的チェック
これをmypyでチェックすることで、プログラムの実行前に関数の使用法のエラーとして検出可能になる。
$ mypy type-hint.py
type-hint.py:8: error: Argument 1 to "concat" has incompatible type "int"; expected "str"
type-hint.py:8: error: Argument 2 to "concat" has incompatible type "int"; expected "str"
type-hint.py:9: error: Argument 2 to "concat" has incompatible type "int"; expected "str"
PyCharmなどのIDEでは型ヒントの情報から、あらかじめ警告表示するサポートがある。
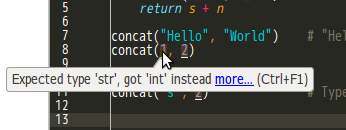
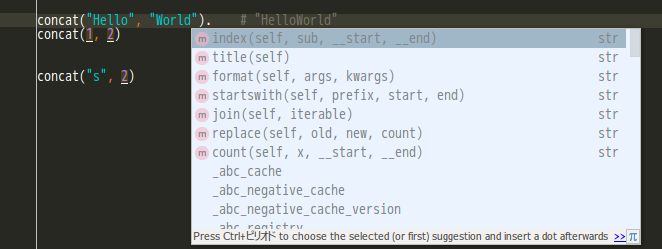
また戻り値が文字列であることが分かるため、関数の実行結果に対しての操作が、文字列に対する操作になるように補完される。
その他にもジェネリック型など他の静的言語と比べても遜色ない型ヒント情報が指定できる。